


Cualquier Mac con Apple Silicon y 16 GB de RAM o más puede ejecutar un modelo de IA local hoy, sin necesidad de suscripciones en la nube. Herramientas como Ollama, LM Studio y OpenClaw convierten un Mac mini, MacBook Pro o Mac Studio en una estación de trabajo de IA privada, capaz de ejecutar modelos de lenguaje de código abierto que rivalizan con ChatGPT y Claude. Los factores clave son la capacidad de RAM y el ancho de banda de memoria, no la última generación de chip. Eso convierte a los Mac reacondicionados con chips M2 Pro, M3 Pro o M4 Pro en algunas de las mejores ofertas en hardware de IA del momento, con un ahorro del 15 al 40 por ciento respecto al precio de un equipo nuevo y un rendimiento idéntico. Si busca el mejor Mac para IA, un modelo reacondicionado es la opción más inteligente.
El fenómeno OpenClaw ha acelerado esta tendencia de forma drástica. Los Mac mini se han agotado en varios mercados mientras la gente se apresura a configurar servidores de IA dedicados en hogares y oficinas. Los precios de Mac de segunda mano han subido notablemente desde febrero de 2026, impulsados en gran parte por la demanda de hardware compatible con IA.
Esta guía cubre qué Mac comprar, cuánta RAM necesita realmente, las mejores herramientas y modelos para ejecutar, y por qué comprar un Mac reacondicionado es la forma más inteligente de construir una estación de trabajo de IA en 2026.
Por qué ejecutar IA en local en su Mac
Los servicios de IA en la nube como ChatGPT Plus y Claude Pro cuestan 20 EUR al mes cada uno. Eso son 240 EUR al año, por servicio. Un Mac mini reacondicionado con Apple Silicon ejecutando modelos locales elimina esos costes recurrentes por completo y le proporciona un ordenador completo.

Pero el coste es solo parte de la historia:
- Privacidad. Sus datos nunca salen de su dispositivo. Ningún prompt se registra en servidores remotos. Sin acceso de terceros. Esto es importante para el cumplimiento del RGPD, políticas de datos corporativas y privacidad personal. El autoalojamiento elimina por completo las preocupaciones sobre transferencia de datos transfronteriza.
- Sin conexión a internet. Tras descargar un modelo una vez (normalmente de 4 a 45 GB), todo funciona sin conexión. Ejecute IA en aviones, en ubicaciones remotas o durante cortes de servicio.
- Sin límites de uso. Sin topes de mensajes diarios, sin limitaciones en horas punta, sin esperas en cola. El modelo funciona tan rápido como su hardware lo permita, tantas veces como quiera.
- Personalización. Elija entre cientos de modelos de código abierto. Ajústelos para tareas específicas. Cambie de modelo en segundos. Sin dependencia de un proveedor.
La IA local no es una versión inferior a los servicios en la nube. Los modelos de código abierto como Qwen 3, Llama 3.3 y DeepSeek R1 ahora igualan o superan el rendimiento de nivel GPT-4 en muchos benchmarks. Ejecutarlos en su Mac significa control total sin coste recurrente. Para quien busca el mejor Mac para IA, la ejecución de un LLM local es la alternativa más rentable.
El efecto OpenClaw: por qué los Mac mini se agotan
OpenClaw es un agente de IA autónomo de código abierto creado por el desarrollador austriaco Peter Steinberger. Publicado inicialmente como "Clawdbot" en noviembre de 2025 y renombrado a OpenClaw en enero de 2026, ha acumulado más de 247.000 estrellas en GitHub y se ha convertido en uno de los proyectos de código abierto de más rápido crecimiento en la historia.
A diferencia de Ollama o LM Studio, OpenClaw no es una herramienta para chatear con IA. Es un agente de IA personal que se conecta a LLMs (en la nube o en local vía Ollama) y utiliza plataformas de mensajería como WhatsApp, Slack, Discord e iMessage como interfaz. Funciona 24/7, monitoriza sus mensajes, ejecuta tareas de varios pasos, gestiona archivos y automatiza flujos de trabajo de forma autónoma. La combinación de OpenClaw con un Mac mini dedicado se ha convertido en la configuración más popular para IA en local.
Por qué OpenClaw impulsa la compra de Mac mini
Dos fuerzas están empujando a la gente a comprar Mac mini dedicados para OpenClaw.
Funcionamiento continuo. OpenClaw está diseñado para funcionar de forma ininterrumpida. Necesita un ordenador que permanezca encendido 24/7 sin disparar la factura de electricidad ni hacer ruido. El Mac mini M4 consume solo de 8 a 15 W en reposo, aproximadamente de 14 a 23 EUR al año en electricidad para funcionamiento ininterrumpido. Es silencioso, ocupa casi nada de espacio con sus 12,7 x 12,7 cm y gestiona largas sesiones sin problemas.
Aislamiento de seguridad. Este es el factor más importante. OpenClaw requiere permisos de Acceso Total al Disco y Accesibilidad para funcionar. Una auditoría de seguridad en enero de 2026 identificó 512 vulnerabilidades, 8 clasificadas como críticas. CVE-2026-25253 permitía la exfiltración de tokens que conducía a la ejecución remota de código. Se publicaron más de 230 scripts maliciosos en ClawHub y GitHub durante la primera semana. Microsoft, Kaspersky, Jamf y SMU recomiendan ejecutar OpenClaw en un dispositivo dedicado y separado en lugar de su ordenador principal.
Esa recomendación crea un caso de uso de compra específico: adquirir un segundo Mac, exclusivamente para su agente de IA, aislado de sus datos personales y archivos de trabajo. Un Mac mini reacondicionado es la forma más económica de hacerlo.
Impacto real en los precios de Mac
La ola de OpenClaw ha movido el mercado de Mac de forma medible:
- Los Mac mini se agotaron en toda China, con sobreprecios de 500 yuanes (68 EUR) o más en comercios de Pekín y Shenzhen
- Los plazos de entrega para configuraciones de Mac con mucha memoria se extendieron a seis semanas a nivel global
- Los precios de Mac de segunda mano subieron considerablemente, con ATRenew aumentando los precios de recompra para incrementar la oferta y los precios de primavera manteniéndose a niveles típicamente vistos durante la demanda máxima de vacaciones
- El CEO de Apple, Tim Cook, reconoció restricciones de suministro en chips avanzados, almacenamiento y memoria
- Casi 1.000 personas hicieron fila en la sede de Tencent en Shenzhen para recibir asistencia presencial con la instalación de OpenClaw
El director de estrategia de ATRenew, Jeremy Ji, declaró a CNBC: "Vemos una demanda creciente de portátiles y PC en general, pero los dispositivos Mac se benefician de esa tendencia por encima de todos los demás."
Qué Mac para OpenClaw
OpenClaw en sí es ligero cuando utiliza APIs en la nube para el razonamiento. La elección de hardware depende de si también desea ejecutar modelos locales a través de él.
| Caso de uso | Mac recomendado | Precio est. reacond. | Por qué |
|---|---|---|---|
| OpenClaw solo con APIs en la nube | Mac mini M4, 16 GB | 440-490 EUR | Suficiente para el agente más 2-3 sub-agentes |
| OpenClaw + modelos locales pequeños (8B) | Mac mini M4, 16 GB, 512 GB SSD | ~650 EUR | Espacio para un modelo local más logs y archivos de memoria |
| OpenClaw + modelos locales potentes (32B) | Mac mini M4 Pro, 48 GB | 1.350-1.490 EUR | Ejecuta Qwen3-Coder:32B en local para llamadas a herramientas, el modelo recomendado por la comunidad para OpenClaw |
| OpenClaw para un equipo (multi-agente) | Mac Studio M2 Ultra, 192 GB | Variable | Sirve a múltiples agentes y usuarios simultáneamente |
Para operación sin monitor (headless), necesitará un adaptador HDMI ficticio (aproximadamente 8 a 10 EUR) para evitar que macOS desactive las funciones de captura de pantalla de las que depende OpenClaw.
Compare precios de Mac mini reacondicionado con Apple Silicon.
Mac mini y Mac Studio como servidores de IA dedicados
La tendencia de OpenClaw forma parte de un cambio más amplio: la gente está configurando Macs como servidores de IA siempre activos y autoalojados para privacidad, reducción de costes e independencia de proveedores en la nube.
Por qué el Mac mini funciona como servidor de IA doméstico
| Factor | Mac mini | PC/GPU típico |
|---|---|---|
| Consumo en reposo | 5-15 W | 50-150 W |
| Consumo en inferencia de IA | 15-30 W | 200-400 W |
| Electricidad anual (24/7) | 14-23 EUR | 140-370 EUR+ |
| Ruido en reposo | Silencioso (sin ventilador) | Audible |
| Factor de forma | 12,7 x 12,7 cm | Torre completa |
| RAM max. para IA | 48-64 GB (toda unificada) | 8-24 GB (VRAM GPU) |
| Complejidad de configuración | Conectar y funcionar | Instalación de drivers, config. CUDA |
Más allá de OpenClaw y los LLM locales, la gente utiliza servidores Mac mini para asistentes de programación privados (alternativas autoalojadas a Copilot), procesamiento de documentos mediante pipelines RAG, servicios de traducción sin conexión, asistentes de voz locales e integraciones de Home Assistant con IA centrada en la privacidad.
Cuándo elegir un Mac Studio en su lugar
El Mac mini tiene un tope de 64 GB de memoria unificada con M4 Pro. Para la mayoría de tareas de IA local, es más que suficiente. Pero si necesita ejecutar modelos de 70B+ parámetros a calidad completa, servir IA a más de unos pocos usuarios simultáneos o ejecutar múltiples agentes OpenClaw para un equipo, el Mac Studio M2 Ultra con chip Ultra es el siguiente nivel.
| Factor | Mac mini M4 Pro | Mac Studio M2/M3 Ultra |
|---|---|---|
| RAM max. | 64 GB | 192 GB |
| Ancho de banda de memoria | 273 GB/s | 800 GB/s |
| Tamaño de modelo cómodo | Hasta 32B | Hasta 200B+ |
| Servicio multiusuario | 1-2 usuarios | 10+ usuarios |
| Consumo energético | 15-30 W | 50-150 W |
| Ideal para | IA personal, un agente OpenClaw | Servidor de IA para equipos, multi-agente, investigación |
Un Mac Studio M2 Ultra con 192 GB a 800 GB/s de ancho de banda genera tokens aproximadamente tres veces más rápido que un Mac mini M4 Pro con el mismo modelo. La diferencia de precio es significativa, pero para equipos que reemplazan varias suscripciones de IA en la nube, los números cuadran rápidamente.
Consulte precios de Mac Studio M2 Ultra reacondicionado.
Qué hace de los Mac el hardware ideal para IA local
Apple Silicon tiene una ventaja estructural sobre los PC tradicionales para ejecutar modelos de lenguaje: la arquitectura de memoria unificada.
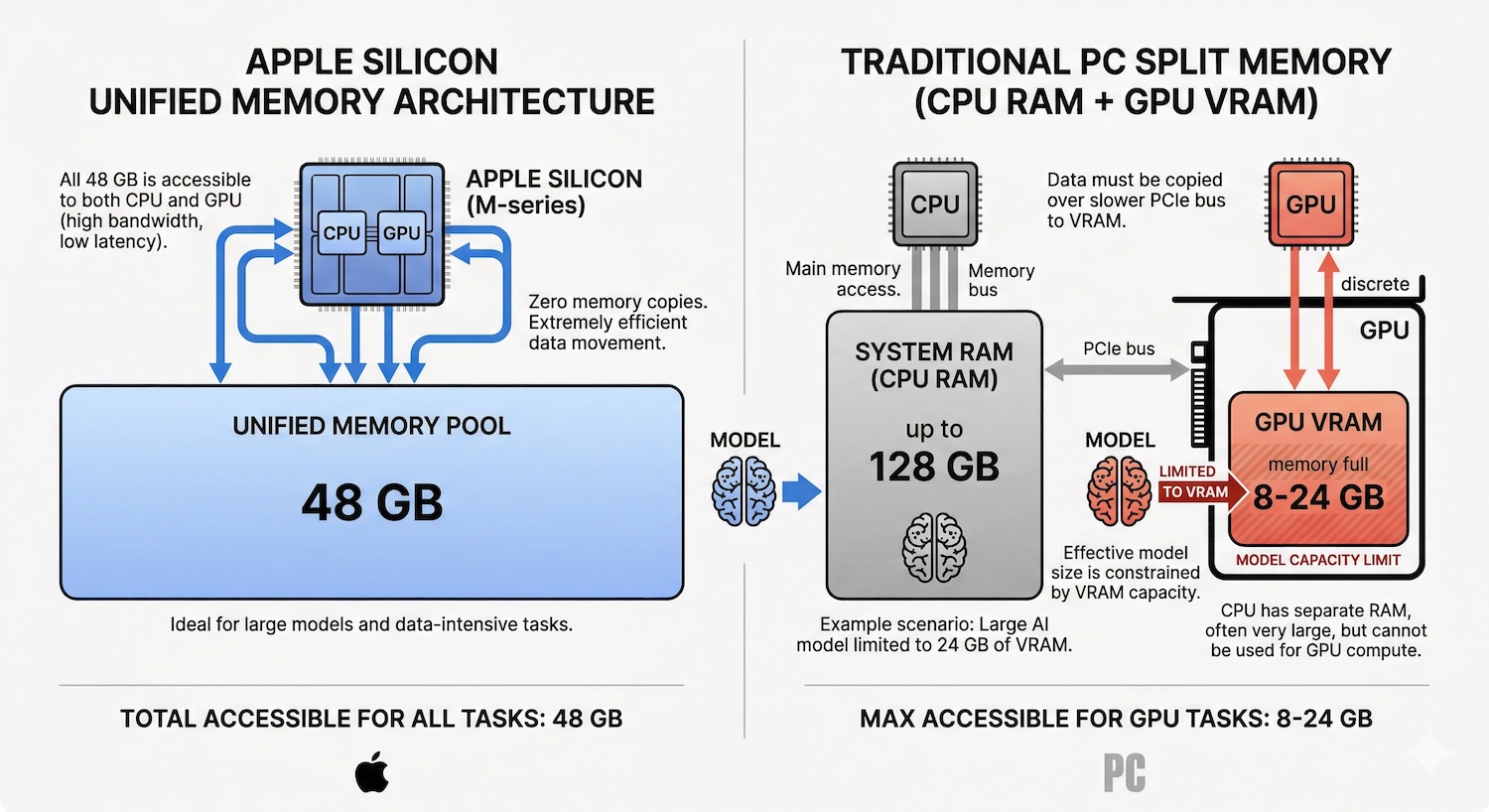
En un PC con Windows, los modelos de IA están limitados por la VRAM de la GPU. Una tarjeta gráfica típica de gaming tiene entre 8 y 24 GB de memoria de video dedicada. Si el modelo no cabe en la VRAM, el rendimiento se desploma. En un Mac, la CPU y la GPU comparten el mismo pool de memoria. Un Mac mini M4 Pro con 48 GB de memoria unificada da al modelo de IA acceso a los 48 GB completos. Sin división artificial entre RAM del sistema y memoria de GPU.
Esto importa porque la velocidad de inferencia de un LLM local depende de dos factores: cuánta memoria hay disponible (determina qué modelos caben) y a qué velocidad se puede leer esa memoria (determina la velocidad de generación de tokens). Apple Silicon ofrece ambos:
| Chip | Ancho de banda | RAM max. | Neural Engine |
|---|---|---|---|
| M1 | 68 GB/s | 16 GB | 11 TOPS |
| M2 | 100 GB/s | 24 GB | 15,8 TOPS |
| M2 Pro | 200 GB/s | 32 GB | 15,8 TOPS |
| M3 Pro | 150 GB/s | 36 GB | 18 TOPS |
| M3 Max | 300-400 GB/s | 128 GB | 18 TOPS |
| M4 | 120 GB/s | 32 GB | 38 TOPS |
| M4 Pro | 273 GB/s | 48 GB | 38 TOPS |
| M4 Max | 546 GB/s | 128 GB | 38 TOPS |
| M5 Pro | 307 GB/s | 48 GB | 38+ TOPS |
| M2 Ultra | 800 GB/s | 192 GB | 31,6 TOPS |
| M3 Ultra | 800 GB/s | 192 GB | 36 TOPS |
Un dato clave para quienes compran reacondicionado: el ancho de banda de memoria importa más que la generación del chip para la inferencia de LLM. Un M3 Max con 400 GB/s de ancho de banda genera tokens más rápido que un M4 Pro a 273 GB/s ejecutando el mismo modelo. Los chips Max y Ultra de generaciones anteriores son excelentes compras reacondicionadas para cargas de trabajo de IA porque ofrecen un ancho de banda superior a precios más bajos.
El framework MLX de Apple, construido específicamente para esta arquitectura, ofrece una inferencia entre un 20 y un 30 por ciento más rápida que llama.cpp en hardware idéntico. Herramientas como LM Studio utilizan MLX automáticamente en Apple Silicon.
Cuánta RAM necesita
La RAM es la especificación más importante para la IA local. La regla general: el archivo del modelo no debería consumir más del 60 al 70 por ciento de la RAM total, dejando espacio para macOS, la ventana de contexto (caché KV) y otras aplicaciones.
| Tamaño del modelo | RAM necesaria | Modelos de ejemplo | Qué puede hacer |
|---|---|---|---|
| 3B-4B | 8 GB mínimo | Llama 3.2 3B, Phi-4 Mini, Gemma 3 4B | Preguntas y respuestas básicas, resumen, ayuda simple con código |
| 7B-8B | 16 GB mínimo | Qwen 3 8B, Llama 3.1 8B, Mistral 7B | Chat general, generación de código, asistencia de redacción |
| 12B-14B | 24 GB mínimo | Qwen 3 14B, DeepSeek-R1-Distill-14B | Razonamiento avanzado, programación compleja, redacción profesional |
| 30B-32B | 48 GB recomendado | Qwen 3 32B, DeepSeek-R1-Distill-32B | Calidad cercana a GPT-4 para la mayoría de tareas |
| 70B | 64-96 GB | Llama 3.3 70B, Qwen 2.5 72B | IA local de nivel frontera, rivaliza con modelos en la nube |
| 200B+ | 128 GB+ | Qwen3 235B-A22B (cuantizado) | Grado investigación, capacidad máxima |
La mayoría de modelos se distribuyen en formatos cuantizados (Q4_K_M es el estándar para uso local). Un modelo de 70B parámetros con cuantización Q4 necesita aproximadamente de 40 a 45 GB de espacio en disco y una cantidad similar en RAM durante la inferencia. Un Mac con 64 GB puede ejecutarlo, pero 96 GB proporciona un margen cómodo.
Para la mayoría de personas, de 16 a 48 GB cubre el punto óptimo práctico. Un Mac de 16 GB ejecuta bien modelos 7B-8B. Un Mac de 48 GB ejecuta modelos 32B que se acercan a la calidad de GPT-4 en tareas de programación, redacción y razonamiento.
Mejores modelos de Mac para IA local (clasificados por valor)

Mejor valor: Mac mini M4 Pro (48 GB)
El Mac mini M4 Pro con 48 GB de memoria unificada es la estación de trabajo de IA con mejor relación calidad-precio disponible en 2026. El mejor Mac para IA si busca equilibrio entre rendimiento y coste. Ejecuta modelos 32B con soltura y puede manejar 70B con cuantización Q4 con cierta presión en el margen. A 273 GB/s de ancho de banda de memoria, las velocidades de generación de tokens alcanzan de 12 a 22 tokens por segundo en modelos 32B, más rápido que la velocidad de lectura cómoda.
Precio nuevo: 1.999 EUR. Mac mini reacondicionado: 1.490 a 1.580 EUR. Eso supone de 400 a 500 EUR de ahorro en hardware idéntico. Consume aproximadamente 30 W bajo carga de IA y funciona casi en silencio.
Compare precios de Mac mini con Apple Silicon en RefurbMe.
Mejor portátil: MacBook Pro M4 Pro (48 GB)
El mismo chip y memoria que el Mac mini M4 Pro, pero con pantalla, teclado y batería. No sacrifica nada en rendimiento de IA y gana portabilidad. Si necesita un portátil de todos modos, el MacBook Pro M4 Pro es la mejor máquina portátil de IA disponible.
Precio nuevo: 2.899 EUR. Reacondicionado: desde 1.704 EUR para la versión de 24 GB y desde 2.679 EUR para 48 GB. Un MacBook Pro reacondicionado con Apple Silicon con chip M4 Pro hace todo lo que hace uno nuevo.
Busque ofertas de MacBook Pro M4 Pro reacondicionado.
Mejor precio de entrada: Mac mini M2 Pro (32 GB)
Los lanzamientos de M4 y M5 han empujado los precios del M2 Pro a la baja en el mercado de reacondicionados. Un Mac mini M2 Pro con 32 GB se encuentra por 770 a 840 EUR, y maneja modelos 14B con fluidez y tiene margen suficiente para uso básico de 32B con cuantización más baja. A 200 GB/s de ancho de banda, es más lento que los chips más recientes pero perfectamente utilizable para tareas de IA cotidianas.
Este es el mejor punto de entrada para quien quiera probar la IA local sin una inversión importante.
Encuentre ofertas de Mac mini reacondicionado con Apple Silicon.
Capacidad máxima: Mac Studio M2 Ultra (192 GB)
Para ejecutar modelos 70B a calidad completa o experimentar con modelos de 200B+ parámetros, nada supera al Mac Studio con chip Ultra. El M2 Ultra con 192 GB de memoria unificada y 800 GB/s de ancho de banda es una máquina de investigación de IA que cabe en un escritorio y consume una fracción de la energía de una configuración GPU comparable.
Consulte precios de Mac Studio M2 Ultra reacondicionado.
Compra inteligente portátil: MacBook Pro M3 Pro (36 GB)
Con la generación M5 empujando las máquinas M3 Pro al canal de reacondicionados, el MacBook Pro M3 Pro con 36 GB es ahora uno de los mejores portátiles para IA en relación calidad-precio. Los precios reacondicionados parten desde unos 2.000 EUR para el modelo de 16 pulgadas en buen estado en Back Market. Con 150 GB/s de ancho de banda de memoria, maneja bien modelos 14B a 30B y ejecuta modelos 7B a velocidades cómodas para uso interactivo.
Si quiere un Mac portátil capaz de ejecutar modelos de IA serios en torno a los 2.000 EUR, el M3 Pro con 36 GB es la respuesta.
Ganga en velocidad: MacBook Pro M3 Max (48-96 GB)
Esta es la elección de conocedores. El M3 Max a 400 GB/s de ancho de banda de memoria genera tokens más rápido que el M4 Pro a 273 GB/s. Con el M5 Pro y M5 Max ya en las estanterías, las máquinas M3 Max están llegando a los canales de reacondicionados con descuentos pronunciados. Un MacBook Pro M3 Max con 48 GB ofrece mejor rendimiento bruto de IA que un M4 Pro nuevo, a menudo a un precio inferior.
Todo en uno: iMac M4 (32 GB)
El iMac reacondicionado con Apple Silicon M4 con 32 GB maneja bien modelos 7B a 14B para uso ocasional de IA. Si desea un único dispositivo con pantalla Retina 4,5K integrada y una capacidad de IA local decente, el iMac cubre ese nicho. No es una máquina pensada para IA, pero cumple para cargas de trabajo más ligeras.
Tabla comparativa
| Modelo de Mac | Opciones de RAM | Ancho de banda | Mejor tamaño de modelo | Precio est. reacond. | Nivel IA |
|---|---|---|---|---|---|
| Mac mini M4 | 16-32 GB | 120 GB/s | 7B-8B | 440-490 EUR | Entrada |
| Mac mini M4 Pro | 24-48 GB | 273 GB/s | 14B-70B | 1.020-1.580 EUR | Mejor valor |
| MacBook Pro M3 Pro | 18-36 GB | 150 GB/s | 7B-30B | desde ~2.000 EUR | Compra inteligente portátil |
| MacBook Pro M4 Pro | 24-48 GB | 273 GB/s | 14B-70B | 1.704-2.679 EUR | Mejor portátil |
| MacBook Pro M3 Max | 48-96 GB | 300-400 GB/s | 32B-70B | desde 2.899 EUR | Ganga en velocidad |
| MacBook Pro M4 Max | 36-128 GB | 546 GB/s | 70B+ | 2.510+ EUR | Pro |
| Mac Studio M2 Ultra | 64-192 GB | 800 GB/s | 70B-200B+ | Variable | Máxima |
| Mac Studio M3 Ultra | 96-192 GB | 800 GB/s | 70B-200B+ | Variable | Máxima |
| iMac M4 | 16-32 GB | 120 GB/s | 7B-14B | 1.300-1.490 EUR | Casual |
Por qué el reacondicionado tiene sentido para cargas de trabajo de IA
La RAM es la opción de configuración más cara en un Mac, y está soldada a la placa base. No se puede ampliar después. Un Mac mini M4 Pro que salte de 24 GB a 48 GB añade 200 EUR al precio de nuevo. En un MacBook Pro, las configuraciones con mucha RAM superan rápidamente los 3.000 EUR.
Los Mac reacondicionados ofrecen el mismo chip, la misma RAM, el mismo rendimiento, simplemente a un precio inferior. Un MacBook Pro reacondicionado con Apple Silicon con 48 GB de memoria unificada rinde de forma idéntica a uno nuevo para inferencia de IA. El silicio no envejece.
Tres razones para comprar reacondicionado para IA en particular:
La ventana de oportunidad del M5. Apple lanzó el M5 Pro y M5 Max en marzo de 2026. Eso significa que las máquinas M3 Pro, M3 Max, M4 Pro y M4 Max están inundando los canales de reacondicionados con los mayores descuentos que hemos visto. Este es el mejor momento para comprar un Mac reacondicionado de generación anterior con chips Pro y Max para IA.
Los modelos de IA no necesitan el último chip. El ancho de banda de memoria y la capacidad de RAM determinan el rendimiento de la IA. Un M3 Max con 96 GB a 400 GB/s es mejor máquina de IA que un M5 nuevo con 24 GB a 307 GB/s. Comprar la generación anterior a menudo significa más RAM por menos dinero, lo que se traduce directamente en ejecutar modelos más grandes y capaces.
Coste de propiedad frente a suscripciones en la nube. La IA local reemplaza el gasto recurrente en la nube por una compra única de hardware. La cuenta es sencilla:
| Gasto | Mensual | Anual | Total a 3 años |
|---|---|---|---|
| ChatGPT Plus | 20 EUR | 240 EUR | 720 EUR |
| Claude Pro | 20 EUR | 240 EUR | 720 EUR |
| Ambas suscripciones | 40 EUR | 480 EUR | 1.440 EUR |
| Mac mini M2 Pro 16 GB reacondicionado | Único | desde 775 EUR | desde 775 EUR |
| MacBook Pro M3 Pro 36 GB reacondicionado | Único | desde 2.000 EUR | desde 2.000 EUR |
Un Mac mini M2 Pro reacondicionado se amortiza frente a ambas suscripciones en menos de dos años. El resto de su vida útil le entrega un ordenador completo, y cada año adicional de uso es ahorro puro.
Ejecutar IA en un Mac reacondicionado es también una apuesta por la sostenibilidad. Prolonga la vida de hardware existente y reduce la demanda energética en centros de datos en la nube. Dos beneficios medioambientales en una sola compra.
RefurbMe compara precios entre Apple Refurbished Store, Amazon Renewed, Back Market y otros vendedores de confianza para que pueda encontrar la mejor oferta en la configuración exacta de RAM y chip que necesita.
¿Ya tiene su Mac? Configure IA local en 10 minutos
Una vez tenga el hardware adecuado, la configuración es rápida. Nuestra guía paso a paso para ejecutar IA local en un Mac (en inglés) cubre la instalación de Ollama y LM Studio, la elección del modelo adecuado para su RAM y su primer prompt. Incluye una tabla de rendimiento con tokens por segundo según el chip, para que sepa qué esperar de su máquina.

1,4Ghz Intel Dual-Core i5 4a gen
4GB de memoria
Año 2014

2,5Ghz Intel Dual-Core i5 3a gen
4GB de memoria
Año 2012

2,7Ghz Intel Dual-Core i7 2a gen
8GB de memoria
Año 2011
Preguntas frecuentes
Última actualización: 19 may 2026 · Publicado el: 28 mar 2026


