


N'importe quel Mac Apple Silicon avec 16 Go de RAM ou plus peut faire tourner un modèle d'IA locale aujourd'hui, sans abonnement cloud. Des outils comme Ollama, LM Studio et OpenClaw transforment un Mac mini, un MacBook Pro ou un Mac Studio en station de travail IA privée, capable d'exécuter des LLM open source qui rivalisent avec ChatGPT et Claude. Les facteurs déterminants sont la capacité mémoire et la bande passante, pas la dernière génération de puce. C'est ce qui fait des Mac reconditionnés équipés de puces M2 Pro, M3 Pro ou M4 Pro certaines des meilleures affaires en matériel IA du moment, avec 15 à 40 % d'économie par rapport au neuf pour des performances identiques.
Le phénomène OpenClaw a considérablement accéléré cette tendance. Les Mac mini se sont retrouvés en rupture de stock sur plusieurs marchés alors que les utilisateurs se précipitent pour installer des serveurs IA dédiés chez eux et dans leurs bureaux. Les prix des Mac d'occasion ont fortement augmenté depuis février 2026, portés par la demande en matériel compatible IA.
Ce guide couvre le choix du meilleur Mac pour IA, la quantité de RAM réellement nécessaire, les meilleurs outils et modèles à utiliser, et pourquoi acheter un Mac reconditionné est la décision la plus judicieuse pour monter une station IA en 2026.
Pourquoi faire tourner une IA locale sur votre Mac ?
Les services d'IA cloud comme ChatGPT Plus et Claude Pro coûtent environ 22 EUR par mois chacun, soit près de 264 EUR par an et par service. Un Mac mini Apple Silicon reconditionné faisant tourner des modèles locaux élimine ces coûts récurrents tout en vous offrant un ordinateur complet.

Mais le coût n'est qu'une partie de l'équation :
- Confidentialité. Vos données ne quittent jamais votre appareil. Aucune requête n'est enregistrée sur des serveurs distants. Aucun accès tiers. C'est essentiel pour la conformité RGPD, les données sensibles soumises au secret professionnel, les politiques de données d'entreprise et la vie privée. L'auto-hébergement supprime tout transfert transfrontalier de données.
- Pas de connexion internet requise. Après le téléchargement initial du modèle (généralement 4 à 45 Go), tout fonctionne hors ligne. Utilisez l'IA dans l'avion, en zone isolée ou pendant une coupure réseau.
- Aucune limite d'utilisation. Pas de quota journalier de messages, pas de ralentissement aux heures de pointe, pas de file d'attente. Le modèle tourne aussi vite que votre matériel le permet, aussi souvent que vous le souhaitez.
- Personnalisation. Choisissez parmi des centaines de modèles open source. Affinez-les pour des tâches spécifiques. Changez de modèle en quelques secondes. Aucune dépendance à un fournisseur.
L'IA locale n'est pas un compromis par rapport aux services cloud. Les modèles open source comme Qwen 3, Llama 3.3 et DeepSeek R1 égalent ou surpassent les performances de GPT-4 sur de nombreux benchmarks. Les faire tourner sur votre Mac vous donne un contrôle total, sans aucun coût récurrent.
L'effet OpenClaw : pourquoi les Mac mini sont en rupture de stock
OpenClaw est un agent IA autonome open source créé par le développeur autrichien Peter Steinberger. Publié initialement sous le nom de « Clawdbot » en novembre 2025 puis renommé OpenClaw en janvier 2026, il a accumulé plus de 247 000 étoiles sur GitHub et figure parmi les projets open source à la croissance la plus rapide de l'histoire.
Contrairement à Ollama ou LM Studio, OpenClaw n'est pas un outil de conversation avec l'IA. C'est un agent IA personnel qui se connecte à des LLM (cloud ou locaux via Ollama) et utilise des plateformes de messagerie comme WhatsApp, Slack, Discord et iMessage comme interface. Il fonctionne 24h/24, surveille vos messages, exécute des tâches multi-étapes, gère des fichiers et automatise des workflows de manière autonome. Considérez-le comme un assistant numérique permanent installé sur votre Mac.
Pourquoi OpenClaw pousse à l'achat de Mac mini
Deux facteurs poussent les utilisateurs à acheter des Mac mini dédiés pour OpenClaw.
Fonctionnement permanent. OpenClaw est conçu pour tourner en continu. Il nécessite un ordinateur allumé 24h/24 sans faire exploser la facture d'électricité ni générer de bruit. Le Mac mini M4 consomme seulement 8 à 15 W au repos, soit environ 14 à 23 EUR par an en électricité pour un fonctionnement continu. Il est silencieux, occupe un espace minimal avec ses 12,7 x 12,7 cm et supporte sans problème les longues périodes d'activité.
Isolation de sécurité. C'est le facteur décisif. OpenClaw nécessite les autorisations Accès complet au disque et Accessibilité pour fonctionner. Un audit de sécurité de janvier 2026 a identifié 512 vulnérabilités, dont 8 classées critiques. La CVE-2026-25253 permettait une exfiltration de tokens menant à une exécution de code à distance. Plus de 230 plugins malveillants ont été publiés sur ClawHub et GitHub la première semaine. Microsoft, Kaspersky, Jamf et SMU recommandent tous d'exécuter OpenClaw sur un appareil dédié et séparé de votre ordinateur principal.
Cette recommandation crée un cas d'usage précis : acheter un second Mac, exclusivement réservé à votre agent IA, isolé de vos données personnelles et professionnelles. Un Mac mini reconditionné est la solution la plus économique.
Impact concret sur les prix des Mac
La vague OpenClaw a sensiblement modifié le marché Mac :
- Les Mac mini se sont retrouvés en rupture de stock en Chine, avec des majorations de 500 yuans (environ 67 EUR) chez les revendeurs de Pékin et Shenzhen
- Les délais de livraison des configurations haute mémoire ont atteint six semaines dans le monde entier
- Les prix des Mac d'occasion ont fortement augmenté, ATRenew ayant relevé ses prix de rachat pour accroître l'offre, et les prix printaniers se maintiennent à des niveaux habituellement observés pendant les périodes de fêtes
- Le PDG d'Apple Tim Cook a reconnu des contraintes d'approvisionnement sur les puces avancées, le stockage et la mémoire
- Près de 1 000 personnes ont fait la queue au siège de Tencent à Shenzhen pour obtenir de l'aide à l'installation d'OpenClaw sur place
Jeremy Ji, directeur de la stratégie d'ATRenew, a déclaré à CNBC : « Nous constatons une demande croissante pour les ordinateurs portables et de bureau dans leur ensemble, mais les appareils Mac profitent de cette tendance plus que tous les autres. »
Quel Mac pour OpenClaw ?
OpenClaw lui-même est léger lorsqu'il utilise des API cloud pour le raisonnement. Le choix du matériel dépend de votre volonté de faire tourner aussi des modèles locaux via l'agent.
| Cas d'usage | Mac recommandé | Prix recond. estimé | Pourquoi |
|---|---|---|---|
| OpenClaw avec API cloud uniquement | Mac mini M4, 16 Go | dès 759 EUR | Suffisant pour l'agent plus 2-3 sous-agents |
| OpenClaw + petits modèles locaux (8B) | Mac mini M4, 16 Go, 512 Go SSD | dès 929 EUR | Place pour un modèle local plus les logs et fichiers mémoire |
| OpenClaw + modèles locaux puissants (14B-32B) | Mac mini M2 Pro, 16 Go | dès 740 EUR | Bande passante de 200 Go/s pour le tool calling local, alternative économique au M4 Pro |
| OpenClaw pour une équipe (multi-agent) | Mac Studio M2 Ultra, 192 Go | Variable (env. 6 999 EUR neuf) | Sert plusieurs agents et utilisateurs simultanément |
Pour un fonctionnement sans écran (headless), vous aurez besoin d'un adaptateur HDMI factice (environ 8 à 10 EUR) afin d'empêcher macOS de désactiver les fonctions de capture d'écran dont OpenClaw dépend.
Comparez les prix des Mac mini Apple Silicon reconditionnés.
Mac mini et Mac Studio comme serveurs IA dédiés
La tendance OpenClaw s'inscrit dans un mouvement plus large : les utilisateurs installent des Mac comme serveurs IA auto-hébergés, fonctionnant en permanence, pour la confidentialité, la réduction des coûts et l'indépendance vis-à-vis des fournisseurs cloud.
Pourquoi le Mac mini fonctionne comme serveur IA domestique
| Critère | Mac mini | PC/Carte graphique classique |
|---|---|---|
| Consommation au repos | 5-15 W | 50-150 W |
| Consommation en inférence IA | 15-30 W | 200-400 W |
| Électricité annuelle (24h/24) | 14-23 EUR | 140-370+ EUR |
| Bruit au repos | Silencieux (sans ventilateur) | Audible |
| Format | 12,7 x 12,7 cm | Tour complète |
| RAM max pour l'IA | 48-64 Go (mémoire unifiée) | 8-24 Go (VRAM GPU) |
| Complexité d'installation | Prêt à l'emploi | Installation de pilotes, configuration CUDA |
Au-delà d'OpenClaw et des LLM locaux, les utilisateurs font tourner des serveurs Mac mini pour des assistants de code privés (alternatives auto-hébergées à Copilot), du traitement de documents via des pipelines RAG, des services de traduction hors ligne, des assistants vocaux locaux et des intégrations Home Assistant avec une IA respectueuse de la vie privée.
Quand choisir un Mac Studio à la place
Le Mac mini plafonne à 64 Go de mémoire unifiée avec la puce M4 Pro. Pour la plupart des tâches d'IA locale, c'est largement suffisant. Mais si vous devez faire tourner des modèles de 70B+ paramètres en qualité maximale, servir l'IA à plus de quelques utilisateurs simultanés ou exécuter plusieurs agents OpenClaw pour une équipe, le Mac Studio M2 Ultra est le cran au-dessus.
| Critère | Mac mini M4 Pro | Mac Studio M2/M3 Ultra |
|---|---|---|
| RAM max | 64 Go | 192 Go |
| Bande passante mémoire | 273 Go/s | 800 Go/s |
| Taille de modèle confortable | Jusqu'à 32B | Jusqu'à 200B+ |
| Service multi-utilisateurs | 1-2 utilisateurs | 10+ utilisateurs |
| Consommation | 15-30 W | 50-150 W |
| Idéal pour | IA personnelle, un agent OpenClaw | Serveur IA d'équipe, multi-agent, recherche |
Un Mac Studio M2 Ultra avec 192 Go et 800 Go/s de bande passante génère des tokens environ trois fois plus vite qu'un Mac mini M4 Pro sur le même modèle. La différence de prix est significative, mais pour les équipes remplaçant plusieurs abonnements IA cloud, le calcul devient vite rentable.
Consultez les prix des Mac Studio M2 Ultra reconditionnés.
Ce qui fait des Mac le matériel idéal pour l'IA locale
Apple Silicon possède un avantage structurel par rapport aux PC classiques pour exécuter des LLM : l'architecture mémoire unifiée.
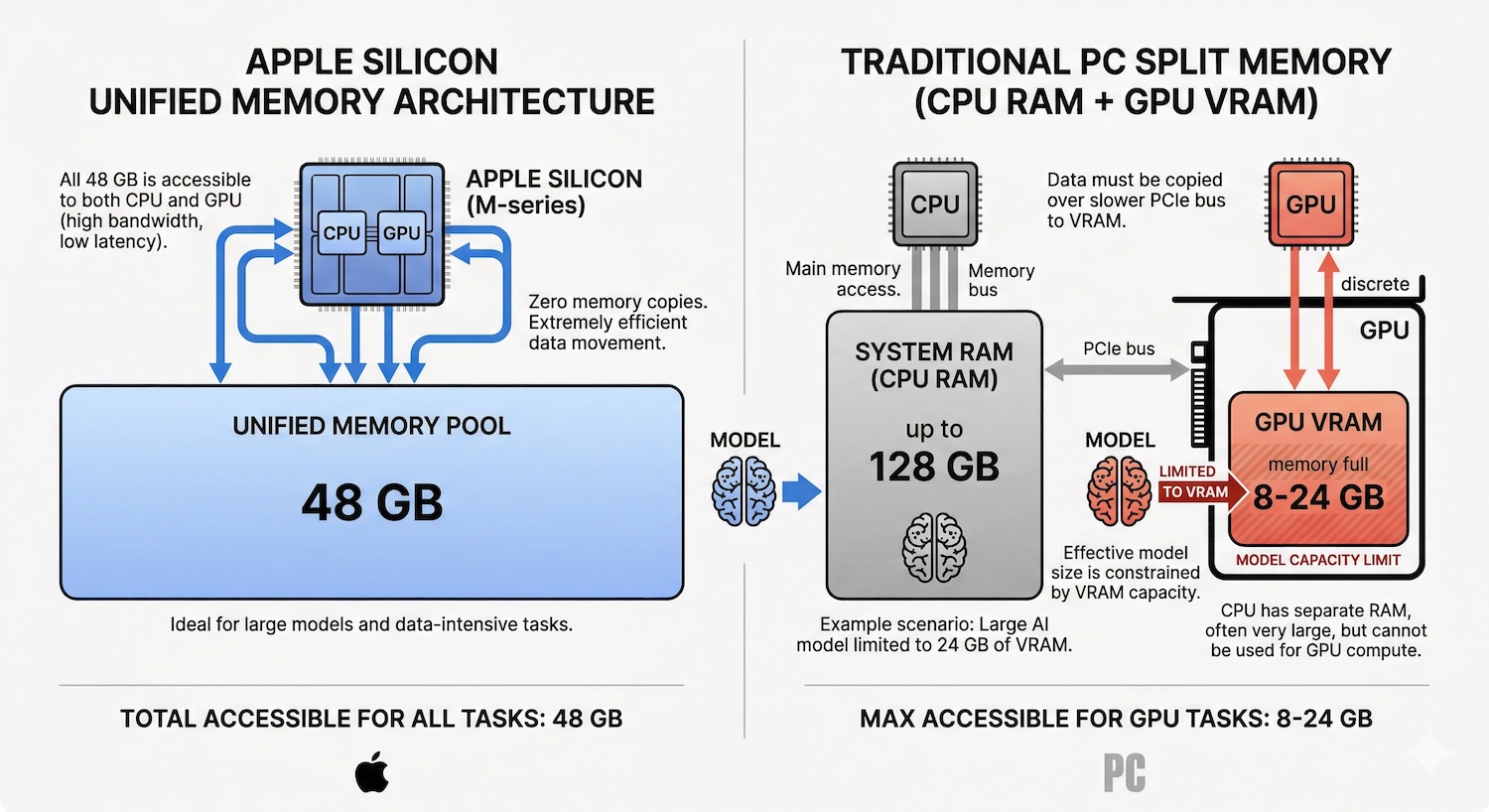
Sur un PC Windows, les modèles d'IA sont limités par la VRAM du GPU. Une carte graphique gaming typique dispose de 8 à 24 Go de mémoire vidéo dédiée. Si le modèle ne tient pas dans la VRAM, les performances s'effondrent. Sur un Mac, le CPU et le GPU partagent le même pool mémoire. Un Mac mini M4 Pro avec 48 Go de mémoire unifiée donne au modèle d'IA accès à la totalité des 48 Go. Pas de séparation artificielle entre RAM système et mémoire GPU.
C'est déterminant car la vitesse d'inférence d'un LLM local dépend de deux facteurs : la quantité de mémoire disponible (qui détermine quels modèles peuvent être chargés) et la vitesse de lecture de cette mémoire (qui détermine la vitesse de génération des tokens). Apple Silicon excelle sur les deux plans :
| Puce | Bande passante mémoire | RAM max | Neural Engine |
|---|---|---|---|
| M1 | 68 Go/s | 16 Go | 11 TOPS |
| M2 | 100 Go/s | 24 Go | 15,8 TOPS |
| M2 Pro | 200 Go/s | 32 Go | 15,8 TOPS |
| M3 Pro | 150 Go/s | 36 Go | 18 TOPS |
| M3 Max | 300-400 Go/s | 128 Go | 18 TOPS |
| M4 | 120 Go/s | 32 Go | 38 TOPS |
| M4 Pro | 273 Go/s | 48 Go | 38 TOPS |
| M4 Max | 546 Go/s | 128 Go | 38 TOPS |
| M5 Pro | 307 Go/s | 48 Go | Neural Engine 16 coeurs amélioré |
| M2 Ultra | 800 Go/s | 192 Go | 31,6 TOPS |
| M3 Ultra | 819 Go/s | 192 Go | Neural Engine 32 coeurs |
Apple positionne le M5 lancé en octobre 2025 autour d'un Neural Engine 16 coeurs amélioré et d'un GPU doté d'accélérateurs neuronaux par coeur, sans publier de chiffre TOPS officiel. La marque met en avant des gains relatifs de performance IA portés par le GPU, pas un score brut du Neural Engine. Pour l'inférence de LLM en local, ce sont surtout la bande passante mémoire et la capacité RAM qui dictent la vitesse réelle.
Point essentiel pour les acheteurs de Mac reconditionnés : la bande passante mémoire compte davantage que la génération de puce pour l'inférence de LLM. Un M3 Max à 400 Go/s génère des tokens plus rapidement qu'un M4 Pro à 273 Go/s sur le même modèle. Les puces Max et Ultra de la génération précédente sont d'excellentes affaires en reconditionné pour les charges de travail IA, car elles offrent une bande passante supérieure à un prix inférieur.
Le framework MLX d'Apple, conçu spécifiquement pour cette architecture, offre une inférence 20 à 30 % plus rapide que llama.cpp sur le même matériel. Des outils comme LM Studio utilisent automatiquement MLX sur Apple Silicon.
De combien de RAM avez-vous besoin ?
La RAM est la caractéristique la plus importante pour l'IA locale. La règle générale : le fichier de votre modèle ne doit pas dépasser 60 à 70 % de la RAM totale, en réservant de la marge pour macOS, la fenêtre de contexte (cache KV) et les autres applications.
| Taille du modèle | RAM nécessaire | Exemples de modèles | Ce que ça permet |
|---|---|---|---|
| 3B-4B | 8 Go minimum | Llama 3.2 3B, Phi-4 Mini, Gemma 3 4B | Questions-réponses basiques, résumé, aide simple au code |
| 7B-8B | 16 Go minimum | Qwen 3 8B, Llama 3.1 8B, Mistral 7B | Chat général, génération de code, aide à la rédaction |
| 12B-14B | 24 Go minimum | Qwen 3 14B, DeepSeek-R1-Distill-14B | Raisonnement avancé, code complexe, rédaction professionnelle |
| 30B-32B | 48 Go recommandé | Qwen 3 32B, DeepSeek-R1-Distill-32B | Qualité proche de GPT-4 pour la plupart des tâches |
| 70B | 64-96 Go | Llama 3.3 70B, Qwen 2.5 72B | IA locale de niveau frontier, rivalise avec les modèles cloud |
| 200B+ | 128 Go+ | Qwen3 235B-A22B (quantifié) | Niveau recherche, capacité maximale |
La plupart des modèles sont distribués en formats quantifiés (Q4_K_M est le standard pour l'utilisation locale). Un modèle de 70B paramètres en quantification Q4 occupe environ 40 à 45 Go sur disque et à peu près autant en RAM pendant l'inférence. Un Mac avec 64 Go peut le faire tourner, mais 96 Go offrent une marge confortable.
Pour la majorité des utilisateurs, 16 à 48 Go couvrent la fourchette idéale. Un Mac à 16 Go fait bien tourner les modèles 7B-8B. Un Mac à 48 Go fait tourner des modèles 32B qui approchent la qualité de GPT-4 en codage, rédaction et raisonnement.
Meilleurs Mac pour l'IA locale (classés par rapport qualité-prix)

Meilleur rapport qualité-prix : Mac mini M4 Pro (48 Go)
Le Mac mini M4 Pro avec 48 Go de mémoire unifiée est la station de travail IA au meilleur rapport qualité-prix dès qu'il apparaît en reconditionné. Il fait tourner les modèles 32B confortablement et gère les 70B en quantification Q4 avec une marge un peu juste. À 273 Go/s de bande passante mémoire, la vitesse de génération atteint 12 à 22 tokens par seconde sur les modèles 32B, ce qui est plus rapide qu'une vitesse de lecture confortable.
Le stock de Mac mini M4 Pro reste rare en reconditionné sur le marché français, où l'on trouve surtout des Mac mini M4 16 Go dès 759 EUR et des M2 Pro dès 740 EUR. Quand il se libère, le M4 Pro reconditionné offre le même silicium que le neuf pour plusieurs centaines d'euros de moins. Il consomme environ 30 W en charge IA et reste quasi silencieux.
Comparez les prix des Mac mini Apple Silicon sur RefurbMe.
Meilleur choix portable : MacBook Pro M4 Pro (48 Go)
La même puce et la même mémoire que le Mac mini M4 Pro, avec en plus un écran, un clavier et une batterie. Vous ne sacrifiez rien en performances IA et gagnez la portabilité. Si vous avez besoin d'un ordinateur portable de toute façon, le MacBook Pro M4 Pro est la meilleure machine IA portable du marché.
Reconditionné : dès 1 659 EUR pour la version 24 Go et dès 2 349 EUR pour 48 Go. Un MacBook Pro Apple Silicon reconditionné avec puce M4 Pro fait exactement la même chose qu'un neuf.
Parcourez les offres de MacBook Pro reconditionné M4 Pro.
Le bon plan d'entrée de gamme : Mac mini M2 Pro (32 Go)
Les lancements des M4 et M5 ont fait chuter les prix des M2 Pro sur le marché du reconditionné. Un Mac mini M2 Pro 16 Go se trouve dès 740 EUR chez reBuy (740 EUR pour le 512 Go SSD, environ 1 099 EUR pour le 1 To), et il gère les modèles 14B sans problème avec assez de marge pour une utilisation basique de modèles 32B en quantification réduite. À 200 Go/s de bande passante, il est plus lent que les puces récentes mais parfaitement utilisable pour les tâches IA courantes.
C'est le meilleur point d'entrée pour quiconque souhaite tester l'IA locale sans investissement majeur.
Trouvez des offres de Mac mini Apple Silicon reconditionnés.
Capacité maximale : Mac Studio M2 Ultra (192 Go)
Pour faire tourner des modèles 70B en qualité maximale ou expérimenter avec des modèles de 200B+ paramètres, rien ne surpasse le Mac Studio équipé d'une puce Ultra. Le M2 Ultra avec 192 Go de mémoire unifiée et 800 Go/s de bande passante est une machine de recherche IA qui tient sur un bureau et consomme une fraction de l'énergie d'un PC à GPU comparable.
Consultez les prix des Mac Studio M2 Ultra reconditionnés.
Le bon plan portable : MacBook Pro M3 Pro (36 Go)
Avec la génération M5 qui pousse les machines M3 Pro vers le marché du reconditionné, le MacBook Pro M3 Pro figure désormais parmi les meilleurs portables IA en termes de rapport qualité-prix. La gamme démarre dès 1 299 EUR pour le 14 pouces 18 Go chez Back Market, et la configuration 36 Go la plus généreuse en mémoire se trouve dès 2 200 EUR pour le 16 pouces. À 150 Go/s de bande passante mémoire, il gère bien les modèles 14B à 30B et fait tourner les modèles 7B à des vitesses confortables pour une utilisation interactive.
Si vous voulez un Mac portable capable de faire tourner des modèles IA sérieux sans dépasser 2 500 EUR, le M3 Pro 36 Go est la réponse.
Le choix malin en vitesse : MacBook Pro M3 Max (48-96 Go)
Voici le choix d'initié. Le M3 Max à 400 Go/s de bande passante mémoire génère des tokens plus vite que le M4 Pro à 273 Go/s. Avec les M5 Pro et M5 Max désormais en vente, les machines M3 Max affluent sur les canaux reconditionnés avec des remises importantes. Un MacBook Pro M3 Max avec 48 Go offre un meilleur débit IA brut qu'un M4 Pro neuf, souvent à un prix inférieur.
Tout-en-un : iMac M3 (24 pouces)
L'iMac Apple Silicon reconditionné M3 se trouve dès 947 EUR sur le marché français et gère correctement les modèles 7B pour une utilisation IA occasionnelle. Si vous voulez un appareil unique avec un écran Retina 4,5K intégré et une capacité d'IA locale correcte, l'iMac remplit ce créneau. Ce n'est pas une machine pensée pour l'IA, et sa mémoire limitée le réserve aux modèles compacts, mais il fait le travail pour les charges légères.
Tableau comparatif
| Modèle Mac | Options RAM | Bande passante | Taille de modèle optimale | Prix recond. estimé | Note IA |
|---|---|---|---|---|---|
| Mac mini M4 | 16-32 Go | 120 Go/s | 7B-8B | dès 759 EUR | Entrée de gamme |
| Mac mini M2 Pro | 16-32 Go | 200 Go/s | 14B-32B | dès 740 EUR | Bon plan serveur IA |
| MacBook Pro M3 Pro | 18-36 Go | 150 Go/s | 7B-30B | dès 1 299 EUR | Bon plan portable |
| MacBook Pro M4 Pro | 24-48 Go | 273 Go/s | 14B-70B | 1 659-2 949 EUR | Meilleur portable |
| MacBook Pro M3 Max | 48-96 Go | 300-400 Go/s | 32B-70B | Variable | Choix malin en vitesse |
| MacBook Pro M4 Max | 36-128 Go | 546 Go/s | 70B+ | Variable | Pro |
| Mac Studio M2 Ultra | 64-192 Go | 800 Go/s | 70B-200B+ | env. 6 999 EUR | Maximum |
| Mac Studio M3 Ultra | 96-192 Go | 819 Go/s | 70B-200B+ | Variable | Maximum |
| iMac M3 | 8-24 Go | 100 Go/s | 7B | dès 947 EUR | Occasionnel |
Pourquoi le reconditionné a du sens pour les charges IA
La RAM est l'option de configuration Mac la plus coûteuse, et elle est soudée à la carte mère. Impossible de l'augmenter par la suite. Sur un Mac mini M4 Pro, passer de 24 Go à 48 Go ajoute environ 230 EUR au prix neuf. Sur un MacBook Pro, les configurations haute mémoire dépassent rapidement les 3 000 EUR.
Les Mac reconditionnés offrent la même puce, la même RAM, les mêmes performances, simplement à un prix inférieur. Un MacBook Pro Apple Silicon reconditionné avec 48 Go de mémoire unifiée fonctionne de manière identique à un neuf pour l'inférence IA. Le silicium ne vieillit pas.
Trois raisons d'acheter du reconditionné pour l'IA en particulier :
La fenêtre de timing M5. Apple a lancé les M5 Pro et M5 Max en mars 2026. Les machines M3 Pro, M3 Max, M4 Pro et M4 Max affluent donc sur les canaux reconditionnés avec les remises les plus importantes que nous ayons observées. C'est le meilleur moment pour acheter des machines Pro et Max de la génération précédente pour l'IA.
Les modèles d'IA n'ont pas besoin de la dernière puce. La bande passante mémoire et la capacité RAM déterminent les performances IA. Un M3 Max avec 96 Go à 400 Go/s est une meilleure machine IA qu'un M5 neuf avec 24 Go à 307 Go/s. Acheter la génération précédente signifie souvent plus de RAM pour moins d'argent, ce qui se traduit directement par la possibilité de faire tourner des modèles plus grands et plus performants.
Coût total vs abonnements cloud. L'IA locale remplace les coûts cloud récurrents par un achat matériel unique. Le calcul est simple :
| Dépense | Mensuel | Annuel | Total sur 3 ans |
|---|---|---|---|
| ChatGPT Plus | 22 EUR | 264 EUR | 792 EUR |
| Claude Pro | 22 EUR | 264 EUR | 792 EUR |
| Les deux abonnements | 44 EUR | 528 EUR | 1 584 EUR |
| Mac mini M2 Pro 16 Go reconditionné | Unique | dès 740 EUR | dès 740 EUR |
| MacBook Pro M3 Pro 18 Go reconditionné | Unique | dès 1 299 EUR | dès 1 299 EUR |
Un Mac mini M2 Pro reconditionné se trouve dès 740 EUR chez reBuy : il est amorti par rapport aux deux abonnements cloud en moins de dix-huit mois. Vous conservez un ordinateur complet pour le reste de la durée de vie de la machine, et chaque année d'utilisation supplémentaire représente une économie pure.
Faire tourner une IA sur un Mac reconditionné est aussi un geste pour la durabilité. Vous prolongez la durée de vie du matériel existant et réduisez la demande énergétique des centres de données cloud. Deux bénéfices environnementaux en un seul achat.
RefurbMe compare les prix entre l'Apple Store Refurbished, Amazon Renewed, Back Market et d'autres vendeurs de confiance pour vous aider à trouver la meilleure offre sur la configuration RAM et puce exacte dont vous avez besoin.
Votre Mac est prêt ? Installez l'IA locale en 10 minutes
Une fois que vous avez le bon matériel, la configuration est rapide. Notre guide pas-à-pas pour faire tourner une IA locale sur Mac (en anglais) couvre l'installation d'Ollama et LM Studio, le choix du modèle adapté à votre RAM et votre première requête. Avec une table de benchmarks tokens par seconde par puce pour savoir à quoi vous attendre de votre machine.

2,6 Ghz Intel Dual-Core i5 4e gen
8 Go de mémoire
Année 2014
1,4 Ghz Intel Dual-Core i5 4e gen
4 Go de mémoire
Année 2014

2,3 Ghz Intel Dual-Core i5 2e gen
2 Go de mémoire
Année 2011
Questions fréquentes
Dernière mise à jour: 3 juin 2026 · Publié le: 28 mars 2026


