


Jeder Apple Silicon Mac mit 16 GB RAM oder mehr kann heute ein lokales KI-Modell ausführen, ganz ohne Cloud-Abo. Tools wie Ollama, LM Studio und OpenClaw verwandeln einen Mac mini, ein MacBook Pro oder einen Mac Studio in eine private KI-Workstation, die Open-Source-Sprachmodelle betreibt, die es mit ChatGPT und Claude aufnehmen können. Entscheidend sind RAM-Kapazität und Speicherbandbreite, nicht die neueste Chip-Generation. Deshalb gehören generalüberholte Macs mit M2 Pro, M3 Pro oder M4 Pro Chips zu den besten Angeboten für KI-Hardware: 15 bis 40 Prozent günstiger als der Neupreis bei identischer Leistung.
Der OpenClaw-Effekt hat diesen Trend beschleunigt. Mac minis waren in mehreren Märkten ausverkauft, weil Menschen dedizierte KI-Server zu Hause und im Büro einrichten. Die Gebrauchtpreise für Macs sind seit Februar 2026 deutlich gestiegen, vor allem durch die Nachfrage nach KI-tauglicher Hardware.
Dieser Ratgeber zeigt, welchen Mac Sie kaufen sollten, wie viel RAM Sie tatsächlich brauchen, welche Tools und Modelle sich am besten eignen und warum ein generalüberholter Mac der klügste Weg zur eigenen KI-Workstation in 2026 ist.
Warum lokale KI auf dem Mac?
Cloud-KI-Dienste wie ChatGPT Plus und Claude Pro kosten jeweils 20 USD pro Monat. Das sind 240 USD pro Jahr, pro Dienst. Ein generalüberholter Apple Silicon Mac mini mit lokalen Modellen macht diese laufenden Kosten überflüssig und gibt Ihnen gleichzeitig einen vollwertigen Computer.

Aber Kosten sind nur ein Teil der Geschichte:
- Datenschutz. Ihre Daten verlassen Ihr Gerät nie. Keine Prompts werden auf externen Servern protokolliert. Kein Zugriff durch Dritte. Das ist relevant für DSGVO-Konformität, Unternehmensdatenrichtlinien und den persönlichen Datenschutz. Selbsthosting eliminiert Bedenken beim grenzüberschreitenden Datentransfer vollständig.
- Kein Internet nötig. Nach dem einmaligen Download eines Modells (typischerweise 4 bis 45 GB) läuft alles offline. Nutzen Sie KI im Flugzeug, an abgelegenen Orten oder bei Netzausfällen.
- Keine Nutzungslimits. Keine täglichen Nachrichtenkontingente, kein Throttling zu Stoßzeiten, kein Warten in Warteschlangen. Das Modell läuft so schnell, wie Ihre Hardware es erlaubt, so oft Sie wollen.
- Anpassbarkeit. Wählen Sie aus Hunderten von Open-Source-Modellen. Passen Sie sie für bestimmte Aufgaben an. Wechseln Sie Modelle in Sekunden. Kein Vendor-Lock-in.
Lokale KI ist kein Downgrade gegenüber Cloud-Diensten. Open-Source-Modelle wie Qwen 3, Llama 3.3 und DeepSeek R1 erreichen oder übertreffen GPT-4-Niveau bei vielen Benchmarks. Sie auf Ihrem Mac zu betreiben bedeutet volle Kontrolle bei null laufenden Kosten.
Der OpenClaw-Effekt: Warum Mac Minis ausverkauft sind
OpenClaw ist ein Open-Source-KI-Agent des österreichischen Entwicklers Peter Steinberger. Erstmals als "Clawdbot" im November 2025 veröffentlicht und im Januar 2026 in OpenClaw umbenannt, hat das Projekt über 247.000 GitHub-Sterne gesammelt und gehört zu den am schnellsten wachsenden Open-Source-Projekten der Geschichte.
Anders als Ollama oder LM Studio ist OpenClaw kein Tool zum Chatten mit KI. Es ist ein persönlicher KI-Agent, der sich mit LLMs verbindet (Cloud oder lokal via Ollama) und Messaging-Plattformen wie WhatsApp, Slack, Discord und iMessage als Schnittstelle nutzt. Er läuft rund um die Uhr, überwacht Ihre Nachrichten, führt mehrstufige Aufgaben aus, verwaltet Dateien und automatisiert Workflows eigenständig. Stellen Sie sich einen permanent aktiven digitalen Assistenten vor, der auf Ihrem Mac lebt.
Warum OpenClaw Mac mini Käufe antreibt
Zwei Faktoren treiben Menschen dazu, dedizierte Mac minis für OpenClaw zu kaufen.
Dauerbetrieb. OpenClaw ist für den Dauerbetrieb konzipiert. Es braucht einen Computer, der 24/7 läuft, ohne hohe Stromkosten zu verursachen oder Lärm zu machen. Der Mac mini M4 verbraucht im Leerlauf nur 8 bis 15 W, etwa 14 bis 23 EUR pro Jahr an Stromkosten für den Dauerbetrieb. Er läuft lautlos, belegt mit 12,7 x 12,7 cm kaum Platz und bewältigt lange Betriebszeiten problemlos.
Sicherheitsisolierung. Das ist der größere Treiber. OpenClaw benötigt Vollzugriff auf die Festplatte und Bedienungshilfen-Berechtigungen. Ein Sicherheitsaudit im Januar 2026 identifizierte 512 Schwachstellen, davon 8 als kritisch eingestuft. CVE-2026-25253 ermöglichte Token-Exfiltration mit Remote-Code-Ausführung. Über 230 bösartige Skript-Plugins wurden innerhalb der ersten Woche auf ClawHub und GitHub veröffentlicht. Microsoft, Kaspersky, Jamf und SMU empfehlen, OpenClaw auf einem dedizierten, separaten Gerät zu betreiben und nicht auf dem Hauptrechner.
Diese Empfehlung schafft einen konkreten Kaufanlass: einen zweiten Mac kaufen, ausschließlich für den KI-Agenten, isoliert von persönlichen Daten und Arbeitsdateien. Ein generalüberholter Mac mini ist der kosteneffizienteste Weg dorthin.
Auswirkungen auf Mac-Preise
Die OpenClaw-Welle hat den Mac-Markt messbar verändert:
- Mac minis waren in ganz China ausverkauft, mit Aufschlägen von 500 Yuan (rund 67 EUR) bei Händlern in Peking und Shenzhen
- Lieferzeiten für Macs mit viel RAM verlängerten sich auf sechs Wochen weltweit
- Gebrauchtpreise für Macs stiegen deutlich; ATRenew erhöhte die Ankaufpreise, um das Angebot zu steigern, und die Frühjahrspreise halten sich auf dem Niveau der sonst typischen Weihnachts-Hochsaison
- Apple-CEO Tim Cook bestätigte Engpässe bei fortschrittlichen Chips, Speicher und RAM
- Fast 1.000 Menschen standen bei Tencent in Shenzhen Schlange für Hilfe bei der OpenClaw-Installation
ATRenews Chief Strategy Officer Jeremy Ji sagte gegenüber CNBC: "Wir sehen die wachsende Nachfrage nach Laptops und PCs insgesamt, aber Mac-Geräte profitieren am stärksten von diesem Trend."
Welcher Mac für OpenClaw?
OpenClaw selbst ist ressourcenschonend, wenn Cloud-APIs für das Reasoning genutzt werden. Die Hardware-Wahl hängt davon ab, ob Sie auch lokale Modelle darüber betreiben wollen.
| Einsatzzweck | Empfohlener Mac | Ca. Refurb-Preis | Warum |
|---|---|---|---|
| OpenClaw nur mit Cloud-APIs | Mac mini M4, 16 GB | 440-490 EUR | Reicht für den Agenten plus 2-3 Sub-Agenten |
| OpenClaw + kleine lokale Modelle (8B) | Mac mini M4, 16 GB, 512 GB SSD | ca. 650 EUR | Platz für ein lokales Modell plus Logs und Memory-Dateien |
| OpenClaw + leistungsstarke lokale Modelle (32B) | Mac mini M4 Pro, 48 GB | 1.350-1.490 EUR | Betreibt Qwen3-Coder:32B lokal für Tool Calling, das von der Community empfohlene Modell für OpenClaw |
| OpenClaw für ein Team (Multi-Agent) | Mac Studio M2 Ultra, 192 GB | Variiert | Bedient mehrere Agenten und Nutzer gleichzeitig |
Für den Headless-Betrieb (ohne Monitor) benötigen Sie einen HDMI-Dummy-Stecker (etwa 8 bis 10 EUR), damit macOS die Bildschirmaufnahme-Funktionen nicht deaktiviert, von denen OpenClaw abhängt.
Generalüberholte Apple Silicon Mac mini Preise vergleichen.
Mac mini und Mac Studio als dedizierte KI-Server
Der OpenClaw-Trend ist Teil einer größeren Entwicklung: Menschen richten Macs als Always-On-KI-Server ein, für Datenschutz, Kostenreduzierung und Unabhängigkeit von Cloud-Anbietern. Der Mac mini eignet sich als kompakter Mac mini Server besonders gut.
Warum der Mac mini als KI-Server zu Hause funktioniert
| Faktor | Mac mini | Typischer PC/GPU-Aufbau |
|---|---|---|
| Leerlauf-Stromverbrauch | 5-15 W | 50-150 W |
| Stromverbrauch bei KI-Inferenz | 15-30 W | 200-400 W |
| Jährliche Stromkosten (24/7) | 14-23 EUR | 140-370 EUR+ |
| Lautstärke im Leerlauf | Lautlos (lüfterlos) | Hörbar |
| Formfaktor | 12,7 x 12,7 cm | Full Tower |
| Max. RAM für KI | 48-64 GB (alles Unified Memory) | 8-24 GB (GPU-VRAM) |
| Setup-Komplexität | Plug and Play | Treiberinstallation, CUDA-Konfiguration |
Über OpenClaw und lokale LLMs hinaus nutzen Menschen Mac mini Server für private Coding-Assistenten (selbstgehostete Copilot-Alternativen), Dokumentenverarbeitung über RAG-Pipelines, Offline-Übersetzungsdienste, lokale Sprachassistenten und Home Assistant-Integrationen mit datenschutzfreundlicher KI.
Wann ein Mac Studio die bessere Wahl ist
Der Mac mini ist bei 64 GB Unified Memory mit dem M4 Pro gedeckelt. Für die meisten lokalen KI-Aufgaben reicht das völlig. Wenn Sie aber 70B+-Parameter-Modelle in voller Qualität betreiben, KI für mehr als wenige gleichzeitige Nutzer bereitstellen oder mehrere OpenClaw-Agenten für ein Team betreiben wollen, ist der Mac Studio M2 Ultra mit Ultra-Chip der nächste Schritt.
| Faktor | Mac mini M4 Pro | Mac Studio M2/M3 Ultra |
|---|---|---|
| Max. RAM | 64 GB | 192 GB |
| Speicherbandbreite | 273 GB/s | 800 GB/s |
| Komfortable Modellgröße | Bis 32B | Bis 200B+ |
| Mehrbenutzer-Betrieb | 1-2 Nutzer | 10+ Nutzer |
| Stromverbrauch | 15-30 W | 50-150 W |
| Ideal für | Persönliche KI, einzelner OpenClaw-Agent | Team-KI-Server, Multi-Agent, Forschung |
Ein Mac Studio M2 Ultra mit 192 GB bei 800 GB/s Bandbreite generiert Token etwa dreimal schneller als ein Mac mini M4 Pro beim selben Modell. Der Preisunterschied ist erheblich, aber für Teams, die mehrere Cloud-KI-Abonnements ersetzen, rechnet sich das schnell.
Generalüberholte Mac Studio M2 Ultra Preise prüfen.
Was Macs für lokale KI ideal macht
Apple Silicon hat einen strukturellen Vorteil gegenüber herkömmlichen PCs für den Betrieb großer Sprachmodelle: die Unified-Memory-Architektur.
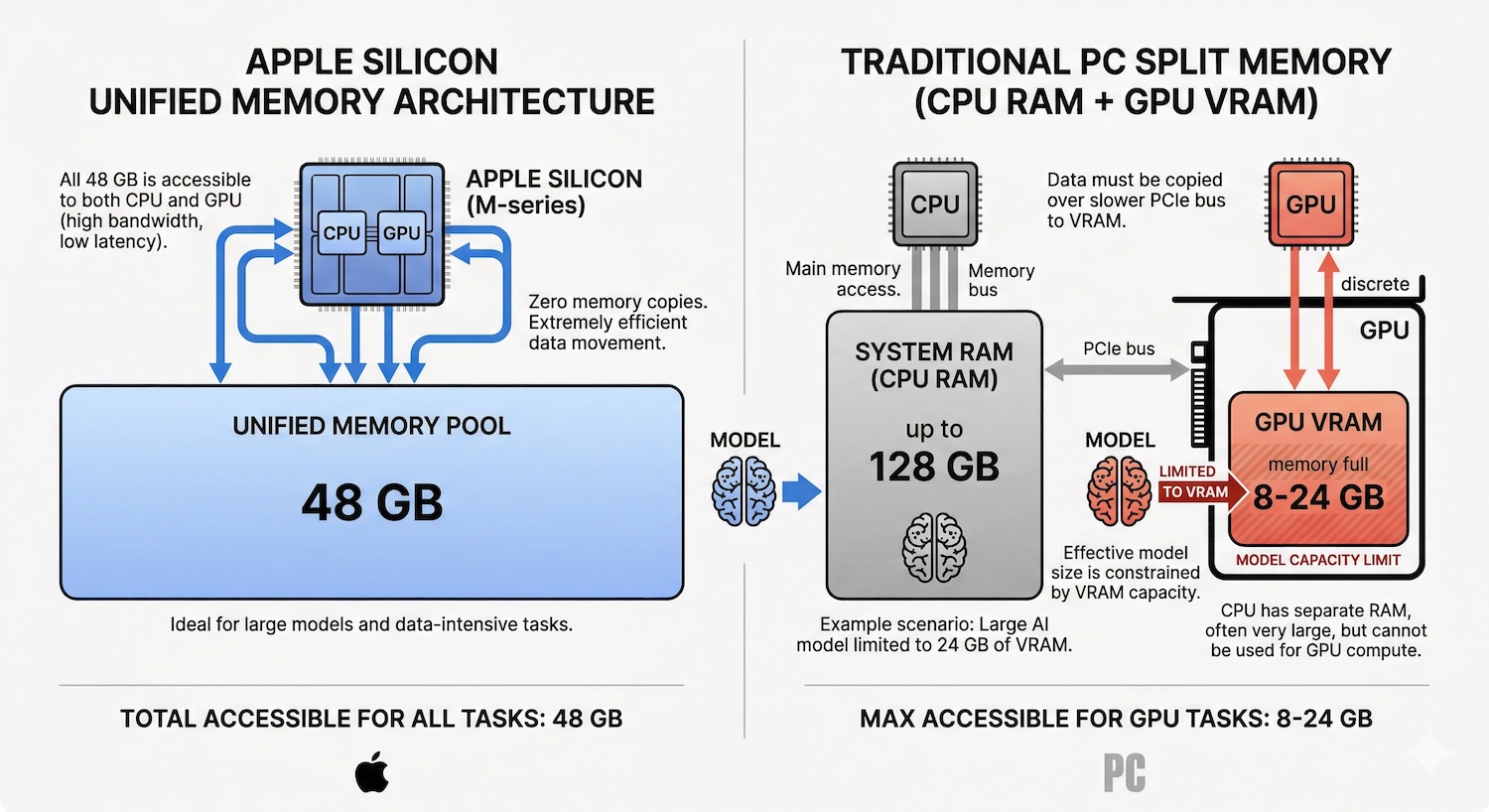
Auf einem Windows-PC sind KI-Modelle durch den GPU-VRAM begrenzt. Eine typische Gaming-GPU hat 8 bis 24 GB dedizierten Videospeicher. Passt das Modell nicht in den VRAM, bricht die Leistung ein. Auf einem Mac teilen sich CPU und GPU denselben Speicherpool. Ein Mac mini M4 Pro mit 48 GB Unified Memory gibt dem KI-Modell Zugriff auf alle 48 GB. Keine künstliche Aufteilung zwischen System-RAM und GPU-Speicher.
Das ist entscheidend, weil die LLM-Inferenzgeschwindigkeit von zwei Faktoren abhängt: wie viel Speicher verfügbar ist (bestimmt, welche Modelle passen) und wie schnell dieser Speicher gelesen werden kann (bestimmt die Token-Generierungsgeschwindigkeit). Apple Silicon liefert beides:
| Chip | Speicherbandbreite | Max. RAM | Neural Engine |
|---|---|---|---|
| M1 | 68 GB/s | 16 GB | 11 TOPS |
| M2 | 100 GB/s | 24 GB | 15,8 TOPS |
| M2 Pro | 200 GB/s | 32 GB | 15,8 TOPS |
| M3 Pro | 150 GB/s | 36 GB | 18 TOPS |
| M3 Max | 300-400 GB/s | 128 GB | 18 TOPS |
| M4 | 120 GB/s | 32 GB | 38 TOPS |
| M4 Pro | 273 GB/s | 48 GB | 38 TOPS |
| M4 Max | 546 GB/s | 128 GB | 38 TOPS |
| M5 Pro | 307 GB/s | 48 GB | 38+ TOPS |
| M2 Ultra | 800 GB/s | 192 GB | 31,6 TOPS |
| M3 Ultra | 800 GB/s | 192 GB | 36 TOPS |
Ein wichtiger Hinweis für Refurbished-Käufer: Die Speicherbandbreite zählt mehr als die Chip-Generation bei der LLM-Inferenz. Ein M3 Max mit 400 GB/s Bandbreite generiert Token schneller als ein M4 Pro mit 273 GB/s beim selben Modell. Max- und Ultra-Chips der Vorgängergeneration sind hervorragende Refurbished-Käufe für KI-Aufgaben, weil sie überlegene Bandbreite zu niedrigeren Preisen bieten.
Apples MLX-Framework, speziell für diese Architektur entwickelt, liefert 20 bis 30 Prozent schnellere Inferenz als llama.cpp auf identischer Hardware. Tools wie LM Studio nutzen MLX auf Apple Silicon automatisch.
Wie viel RAM brauchen Sie?
RAM ist die wichtigste Spezifikation für lokale KI. Die Faustregel: Ihre Modelldatei sollte nicht mehr als 60 bis 70 Prozent des Gesamt-RAM belegen, damit Platz für macOS, das Kontextfenster (KV-Cache) und andere Anwendungen bleibt.
| Modellgröße | RAM benötigt | Beispielmodelle | Was es kann |
|---|---|---|---|
| 3B-4B | Minimum 8 GB | Llama 3.2 3B, Phi-4 Mini, Gemma 3 4B | Einfache Fragen und Antworten, Zusammenfassungen, einfache Programmierhilfe |
| 7B-8B | Minimum 16 GB | Qwen 3 8B, Llama 3.1 8B, Mistral 7B | Allgemeiner Chat, Code-Generierung, Schreibhilfe |
| 12B-14B | Minimum 24 GB | Qwen 3 14B, DeepSeek-R1-Distill-14B | Starkes Reasoning, komplexe Programmierung, professionelles Schreiben |
| 30B-32B | 48 GB empfohlen | Qwen 3 32B, DeepSeek-R1-Distill-32B | Nahezu GPT-4-Qualität für die meisten Aufgaben |
| 70B | 64-96 GB | Llama 3.3 70B, Qwen 2.5 72B | Lokale KI auf Spitzenniveau, konkurriert mit Cloud-Modellen |
| 200B+ | 128 GB+ | Qwen3 235B-A22B (quantisiert) | Forschungsqualität, maximale Leistungsfähigkeit |
Die meisten Modelle werden in quantisierten Formaten verteilt (Q4_K_M ist der Standard für den lokalen Einsatz). Ein 70B-Parameter-Modell in Q4-Quantisierung benötigt etwa 40 bis 45 GB Speicherplatz und etwa genauso viel RAM während der Inferenz. Ein Mac mit 64 GB kann es betreiben, aber 96 GB bieten komfortablen Spielraum.
Für die meisten Nutzer deckt 16 bis 48 GB den praktischen Sweetspot ab. Ein Mac mit 16 GB betreibt 7B-8B-Modelle gut. Ein Mac mit 48 GB betreibt 32B-Modelle, die bei Coding-, Schreib- und Reasoning-Aufgaben an GPT-4-Qualität heranreichen.
Beste Mac-Modelle für lokale KI (nach Preis-Leistung)

Bestes Preis-Leistungs-Verhältnis: Mac mini M4 Pro (48 GB)
Der Mac mini M4 Pro mit 48 GB Unified Memory ist die KI-Workstation mit dem besten Preis-Leistungs-Verhältnis in 2026. Er betreibt 32B-Modelle komfortabel und bewältigt 70B in Q4-Quantisierung mit etwas Spielraum. Bei 273 GB/s Speicherbandbreite erreicht die Token-Generierung 12 bis 22 Token pro Sekunde bei 32B-Modellen, das ist schneller als angenehme Lesegeschwindigkeit.
Neupreis: 2.199 EUR. Generalüberholt (Mac refurbished): 1.490 bis 1.580 EUR. Das sind 300 bis 400 EUR Ersparnis bei identischer Hardware. Er verbraucht etwa 30 W unter KI-Last und läuft nahezu lautlos.
Generalüberholte Apple Silicon Mac mini Preise auf RefurbMe vergleichen.
Beste mobile Lösung: MacBook Pro M4 Pro (48 GB)
Derselbe Chip und Speicher wie der Mac mini M4 Pro, plus Bildschirm, Tastatur und Akku. Sie opfern nichts an KI-Leistung und gewinnen Mobilität. Wenn Sie ohnehin ein Laptop brauchen, ist das MacBook Pro M4 Pro die beste tragbare KI-Maschine auf dem Markt.
Neupreis: 3.199 EUR. Generalüberholt: ab 1.633 EUR für die 24-GB-Variante und ab 2.569 EUR für 48 GB. Ein generalüberholtes Apple Silicon MacBook Pro mit M4 Pro Chip leistet exakt das Gleiche wie ein neues.
Generalüberholte MacBook Pro M4 Pro Angebote ansehen.
Budget-Sweetspot: Mac mini M2 Pro (32 GB)
Die M4- und M5-Launches haben die M2 Pro Preise auf dem Refurbished-Markt deutlich gedrückt. Einen Mac mini M2 Pro mit 32 GB finden Sie für 770 bis 840 EUR, und er bewältigt 14B-Modelle flüssig mit genug Spielraum für einfache 32B-Nutzung bei niedrigerer Quantisierung. Bei 200 GB/s Bandbreite ist er langsamer als neuere Chips, aber für alltägliche KI-Aufgaben bestens geeignet.
Das ist der beste Einstiegspunkt für alle, die lokale KI ausprobieren wollen, ohne viel zu investieren.
Generalüberholte Apple Silicon Mac mini Angebote finden.
Maximale Leistungsfähigkeit: Mac Studio M2 Ultra (192 GB)
Für den Betrieb von 70B-Modellen in voller Qualität oder Experimente mit 200B+-Parameter-Modellen ist der Mac Studio mit Ultra-Chip unübertroffen. Der M2 Ultra mit 192 GB Unified Memory und 800 GB/s Bandbreite ist eine KI-Forschungsmaschine, die auf einen Schreibtisch passt und einen Bruchteil der Energie eines vergleichbaren GPU-Setups verbraucht.
Generalüberholte Mac Studio M2 Ultra Preise prüfen.
Tragbarer Budget-Tipp: MacBook Pro M3 Pro (36 GB)
Da die M5-Generation M3-Pro-Geräte in die Refurbished-Kanäle drückt, ist das MacBook Pro M3 Pro mit 36 GB jetzt einer der besten KI-Laptops für das Geld. Refurbished-Preise beginnen bei etwa 1.900 EUR für das 16-Zoll-Modell in gutem Zustand bei Back Market. Mit 150 GB/s Speicherbandbreite bewältigt es 14B- bis 30B-Modelle gut und betreibt 7B-Modelle in komfortabler Geschwindigkeit für den interaktiven Einsatz.
Wenn Sie einen tragbaren Mac wollen, der ernsthafte KI-Modelle unter 2.000 EUR betreibt, ist der M3 Pro mit 36 GB die Antwort.
Geheimtipp Geschwindigkeit: MacBook Pro M3 Max (48-96 GB)
Hier kommt der Insidertipp. Der M3 Max mit 400 GB/s Speicherbandbreite generiert Token schneller als der M4 Pro mit 273 GB/s. Seit der M5 Pro und M5 Max im Handel sind, fließen M3 Max Geräte zu starken Rabatten in die Refurbished-Kanäle. Ein MacBook Pro M3 Max mit 48 GB bietet besseren KI-Durchsatz als ein nagelneuer M4 Pro, oft zu einem niedrigeren Preis.
All-in-One: iMac M4 (32 GB)
Der generalüberholte Apple Silicon iMac M4 mit 32 GB bewältigt 7B- bis 14B-Modelle gut genug für gelegentliche KI-Nutzung. Wenn Sie ein einzelnes Gerät mit integriertem 4,5K Retina-Display und ordentlicher lokaler KI-Leistung wollen, füllt der iMac diese Nische. Er ist keine KI-First-Maschine, aber für leichtere Workloads erledigt er die Aufgabe.
Vergleichstabelle
| Mac-Modell | RAM-Optionen | Bandbreite | Beste Modellgröße | Ca. Refurb-Preis | KI-Bewertung |
|---|---|---|---|---|---|
| Mac mini M4 | 16-32 GB | 120 GB/s | 7B-8B | 440-490 EUR | Einstieg |
| Mac mini M4 Pro | 24-48 GB | 273 GB/s | 14B-70B | 1.020-1.580 EUR | Bestes Preis-Leistungs-Verhältnis |
| MacBook Pro M3 Pro | 18-36 GB | 150 GB/s | 7B-30B | ab ~1.900 EUR | Tragbarer Budget-Tipp |
| MacBook Pro M4 Pro | 24-48 GB | 273 GB/s | 14B-70B | 1.633-2.569 EUR | Beste mobile Lösung |
| MacBook Pro M3 Max | 48-96 GB | 300-400 GB/s | 32B-70B | ab 2.754 EUR | Geheimtipp |
| MacBook Pro M4 Max | 36-128 GB | 546 GB/s | 70B+ | 2.520 EUR+ | Profi |
| Mac Studio M2 Ultra | 64-192 GB | 800 GB/s | 70B-200B+ | Variiert | Maximum |
| Mac Studio M3 Ultra | 96-192 GB | 800 GB/s | 70B-200B+ | Variiert | Maximum |
| iMac M4 | 16-32 GB | 120 GB/s | 7B-14B | 1.300-1.490 EUR | Gelegentlich |
Warum generalüberholt für KI-Workloads sinnvoll ist
RAM ist die teuerste Mac-Konfigurationsoption, und er ist fest auf der Platine verlötet. Ein späteres Upgrade ist nicht möglich. Beim Mac mini M4 Pro kostet der Sprung von 24 GB auf 48 GB 200 EUR Aufpreis zum Neupreis. Beim MacBook Pro überschreiten High-RAM-Konfigurationen schnell 3.000 EUR.
Generalüberholte Macs (Apple generalüberholt) bieten denselben Chip, denselben RAM, dieselbe Leistung, nur zu einem niedrigeren Preis. Ein generalüberholtes Apple Silicon MacBook Pro mit 48 GB Unified Memory arbeitet bei der KI-Inferenz identisch wie ein neues. Das Silizium altert nicht.
Drei Gründe, warum generalüberholte Macs gerade für KI die kluge Wahl sind:
Das M5-Zeitfenster. Apple hat den M5 Pro und M5 Max im März 2026 vorgestellt. Das bedeutet, dass M3 Pro, M3 Max, M4 Pro und M4 Max Geräte in großer Zahl zu den steilsten Rabatten in die Refurbished-Kanäle fließen. Jetzt ist der beste Zeitpunkt, Vorgängergeneration Pro- und Max-Maschinen für KI zu kaufen.
KI-Modelle brauchen nicht den neuesten Chip. Speicherbandbreite und RAM-Kapazität bestimmen die KI-Leistung. Ein M3 Max mit 96 GB bei 400 GB/s ist eine bessere KI-Maschine als ein nagelneuer M5 mit 24 GB bei 307 GB/s. Die Vorgängergeneration zu kaufen bedeutet oft mehr RAM für weniger Geld, was sich direkt in der Möglichkeit niederschlägt, größere und leistungsfähigere Modelle zu betreiben. Der Suchbegriff "LLM lokal" zeigt: immer mehr Deutsche setzen auf lokale KI.
Betriebskosten vs. Cloud-Abos. Lokale KI ersetzt laufende Cloud-Kosten durch eine einmalige Hardware-Investition. Die Rechnung ist klar:
| Ausgabe | Monatlich | Jährlich | Über 3 Jahre |
|---|---|---|---|
| ChatGPT Plus | 20 USD | 240 USD | 720 USD |
| Claude Pro | 20 USD | 240 USD | 720 USD |
| Beide Abos zusammen | 40 USD | 480 USD | 1.440 USD |
| Generalüberholter Mac mini M2 Pro 16 GB | Einmalig | ab 775 EUR | ab 775 EUR |
| Generalüberholtes MacBook Pro M3 Pro 36 GB | Einmalig | ab 1.900 EUR | ab 1.900 EUR |
Ein generalüberholter Mac mini M2 Pro amortisiert sich gegenüber beiden Cloud-Abos in weniger als zwei Jahren. Den Rest der Nutzungszeit haben Sie einen vollwertigen Computer, und jedes weitere Jahr ist reine Ersparnis.
KI auf einem generalüberholten Mac zu betreiben ist auch ein Nachhaltigkeitsgewinn. Sie verlängern die Lebensdauer vorhandener Hardware und reduzieren den Energiebedarf von Cloud-Rechenzentren. Zwei Umweltvorteile mit einem Kauf.
RefurbMe vergleicht Preise von Apple Refurbished Store, Amazon Renewed, Back Market und weiteren vertrauenswürdigen Händlern, damit Sie das beste Angebot für die exakte RAM- und Chip-Konfiguration finden, die Sie brauchen.
Mac bereit? Lokale KI in 10 Minuten einrichten
Sobald Sie die passende Hardware haben, ist die Einrichtung schnell erledigt. Unser Schritt-für-Schritt-Leitfaden zur Einrichtung lokaler KI auf dem Mac (auf Englisch) führt durch die Installation von Ollama und LM Studio, die Wahl des passenden Modells für Ihren RAM und Ihren ersten Prompt. Inklusive Benchmark-Tabelle mit Tokens pro Sekunde nach Chip, damit Sie wissen, was Sie von Ihrem Gerät erwarten können.

1,4 Ghz Intel Dual-Core i5 4. gen
4 GB Speicher
Jahr 2014

2,5 Ghz Intel Dual-Core i5 3. gen
4 GB Speicher
Jahr 2012

2,7 Ghz Intel Dual-Core i7 2. gen
8 GB Speicher
Jahr 2011
FAQ
Letzte Aktualisierung: 19. Mai 2026 · Erstveröffentlichung: 28. März 2026


